Transformers are the workhorse of modern sequence modeling, achieving remarkable performance on a variety of tasks, but they have unavoidable inefficiencies. Specifically, when it comes to memory and compute requirements to predict the next token of a sequence of length. Recently, there is growing interest in models that use a fixed-size latent state that does not depend on the sequence length, which we refer to as “generalized state space models” (GSSMs).
GSSMs have demonstrated impressive performance, but it is not yet clear what these models sacrifice for their improved efficiency, if anything. Well that’s what exactly this paper has found out. It seems that GSSMs are promising in terms of inference-time efficiency but are limited compared to transformer models on tasks that require copying from the input context.
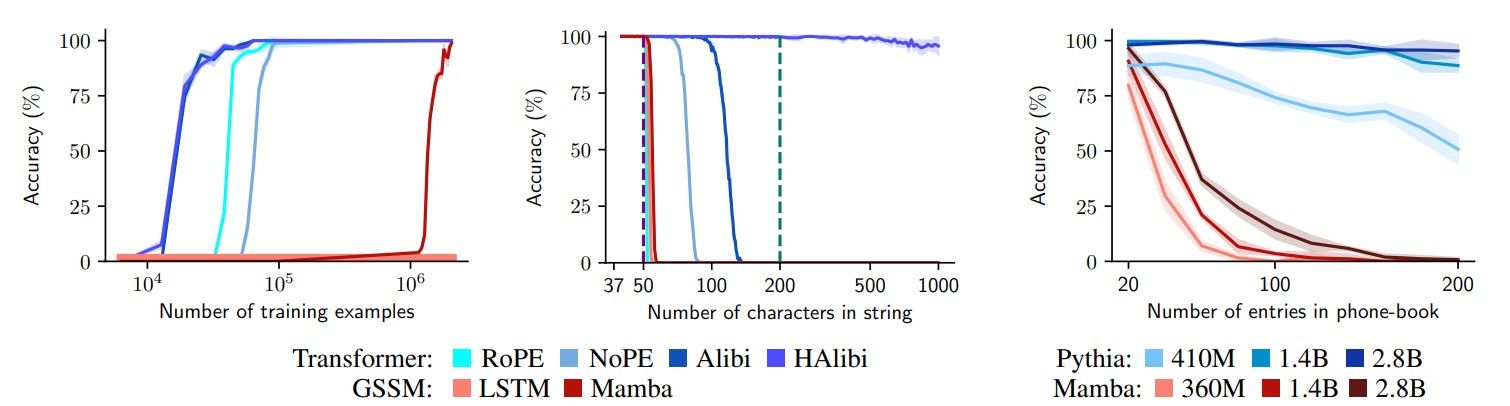
To understand this gap in capabilities experimentation was carried out to copy strings of length that are exponential in the number of heads of the transformer under the following scenarios.
Copying: training efficiency. Here the train models copy strings of length ≤ 300 and evaluate string-level accuracy on strings of length 300. Transformers train much faster than GSSMs.
Copying: length generalization. Here train models copy strings of length ≤ 50 until all models are perfect in-distribution and evaluate string-level accuracy. Evaluating on longer inputs, the transformer models dramatically outperform the GSSMs.
Lookup with pretrained models. Here the task requires looking up and retrieving a number from a “phone book” of varying length that is entirely in context. Pythia (a transformer model) substantially outperforms Mamba (a GSSM) across model sizes.
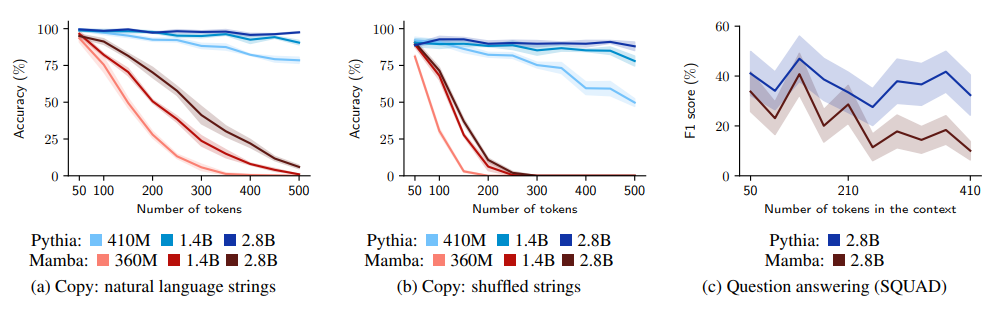
Copy: natural language strings. It compares pretrained models on their ability to copy natural language strings sampled from C4 of varying lengths and report string-level accuracy. The transformer models substantially outperform the GSSMs.
Copy: shuffled strings. To test whether it mattered that the strings were in natural language, randomly shuffle the word order of the strings from the previous experiment. it was found that this degrades performance, especially for the Mamba models.
Overall transformers are better than GSSMs at copying from their input context. However, SSMs have many advantages over transformers when it comes to memory and computational complexity as well as generating long consistent text. Future work should focus on building hybrid architectures that endow state space models with an attention-like mechanism, allowing them to retrieve relevant pieces of text from their input. What do you think ?
So why size of input context is so much important in LLMs. In order to understand this let’s look at GPU level. Modern GPUs have a “problem”: they’re too fast. GPUs have become very fast at performing calculations, insomuch that the speed of computation (FLOPs) is much higher than the memory bandwidth (GB/s) or speed of data transfer between memory areas. For example, an NVIDIA A100 can perform 19.5 TFLOPs while having a memory bandwidth of 2TB/s, which is 40 times slower considering each operation is 32 bit.
This means that sometimes the bottleneck is not how many operations we perform, but how much data transfer our operations need, and that depends on the size and the quantity of the tensors involved in our calculations. For example, computing the same operation on the same tensor N time may be faster than computing the same operation on N different tensors, even if they have the same size, this is because the GPU may need to move the tensors around. That what happens during memory-intensive tasks such as copying long strings, retrieval and few-shot question answering.
So the goal should not only be to optimize the number of operations we do, but also minimize the memory access/transfers that we perform.